If you don't know me (which is very likely considering I despise social media and live a pretty quiet life), I'm a seasoned Scala developer who puts an excruciating amount of effort into reducing the amount of work I have to do during my day job. I absolutely despise repetitive tasks, and require an extreme amount of energy to ensure I'm not f***ing them up. It's no surprise that I tend to develop a strong infatuation for any tool/language that offers to precisely and correctly validate what I'm doing. It's no surprise either that I have a gigantic aversion for anything that doesn't include such validation, which is a category that includes, in particular, dynamically typed languages, and CI/CD pipelines that combine bash and yaml and require you to execute what you've written to discover that you've blatantly messed up somehow, but I digress ...
So anyway, I've been playing with Unison lately, and have had a good amount of fun and want to share the excitement. The problem, however, is that it's quite hard to describe what Unison is in just a few words: it is not "just" a new programming language, it subverts expectations around a number long-standing habits of software developers and it may be difficult to get a feel for why it is exciting without diving into it yourself.
In this article, I am going to try and share elements of the mental model I've built around it, and reflections on what it improves over the status quo.
A word of warning though: I will not talk much about the actual Unison programming language here as the official website contains some very good documentation and tutorials to get started.
What is Unison, anyway?
Unison is an ecosystem of tools that aim at making it borderline trivial to build and ship distributed systems. (I'm not being hyperbolic here, I do mean trivial rather than simpler/easier).
It is maintained by Unison computing, a public benefit corporation who has amongst its founders the authors of the famous Scala Red Book (who are regarded as smart folks).
The Unison ecosystem contains in particular:
- a high-level functional-programming language (unison-lang) that embeds constructs to easily express and deploy distributed systems.
- a code storing platform (unison-share) that makes use of different foundations than file-based version control systems. It's essentially a "github for unison".
- a code management tool (unison codebase manager) that provides new ways of interacting with code. It's a combination of a compiler, a code explorer, a refactoring tool, and "git for unison".
- A paid cloud platform (unison-cloud), where you can deploy your unison applications, without having to package them in docker. It's worth noting that in this list, the cloud platform is the only closed-source product. (You didn't think it was all gonna be free, did you? People gotta eat!)
Put together, these tools offer a complete and cohesive re-imagination of what it means to write and deploy cloud applications. The fact that Unison is built on bespoke foundations (as opposed to building status quo of git/github/docker) opens the door to very interesting properties that are likely to translate to monetary savings. However, its blatant departure from the established tools that are the bread-and-butter of the vast majority of engineering organisations may seem extravagant, and one needs to get their hands dirty to get a feel for the rationale.
So why is Unison seemingly re-inventing the wheel at every level of the process of building distributed applications?
Some problems with the status quo
To the credit of the people involved in the development of Unison, their marketing strategy does not seem to involve smear-campaigns that try to make you, poor soul, feel bad about the tools you use in your day-to-day tasks. But my ever-unsatisfied mind can't help but obsess over those things, so I'm gonna try and pinpoint some aspects of the status quo that objectively suck.
The problem of packaging applications
Let's take a look at the current status quo of cloud applications, through the lens of a JVM application packaged in a docker image.
- JVM functions (methods) are indexed by name and bundled in class files
- Jars are bundles of class files. It's common for a jar to weigh around 1MB.
- A JVM application is composed of a set of jars, that often collectively weigh about 100MB
- A docker image packaging a JVM application is a ordered, layered bundled set of files. It's common for a dockerised JVM application.
Whenever a single function in a jar changes, the following things happen:
- method changes, therefore class file needs updating
- class bundle changes therefore jar needs re-bundling
- jar bundle changes, therefore the set of jars that composes a JVM application changes
- set of jars changes, therefore the corresponding docker layer as well as all the subsequent layers need rebuilding

So a simple change of a few characters in a Java/Scala program can lead to 100MB worth of re-packaging before the program can be deployed, because the various layers of bundles imply an increasing amount of coupling between things that are often not related logically.
The problem of indexing code
To make the matter worse, in a JVM application, things are indexed by human-given names. Over time, the definition of those things may change in meaning or signature: it's impossible for several versions of something identified by a name to live at the same time in an application, as it leads to infamous binary compatibility problems. This can happen, for instance, when functions from two jars depend on different versions of a function shipped in a third jar. Library authors need to be extremely careful about not breaking binary compatibility for their users, and the users have to be able to understand how to pinpoint library dependency problems and resolve them. This is a fair amount of overhead that everybody hates.
I recommend this excellent talk from Sebastien Doeraene (the author of Scala-js) on source/binary compatibility in Scala, to get a glimpse of the monstrous complexity that library developers have to deal with.
The problem of deploying applications
We backend engineers tend to think in terms of two opposite paradigms when it comes to applications building and deployment: monoliths and micro-services.
Monoliths
Historically, cloud applications were written in a monolithic way: the whole cloud application is a single unit/bundle that is developed and deployed as a whole.
This paradigm has scaling problems: build/deployment times tend to grow prohibitively large, as the whole of a cloud application is built as a single bundle. Organisations have to come-up with costly/elaborate build strategies (which has led to build-tools specialised for mono-repos such as Bazel/Pants, often requiring dedicated teams for their maintenance and operations). Teams are not able to make independent decisions regarding the library versions they use to build their components of the monolithic application, as binary compatibility problems could be crippling. In addition, components are competing for resources of the machines the monolith runs on (CPU, memory, file handles).
On the other hand, in a monolith, the application is compiled as a whole, which is helpful to guarantee that components are on the same page with respect of the function calls that let them communicate with one-another. Moreover, data moving from component to component is only transiting through the memory of the machine, which is more efficient than having to send the data over the wire.

(arrows == interactions, rectangle == application node, large disks == components, small disks and diamonds == libraries)
Micro-services
Nowadays, the micro-service paradigm is preferred: separate teams maintain independent bundles and are responsible for deploying and scaling it independently from the rest of the system. These teams decide for themselves what libraries/versions to use (reducing but not eliminating the risk for binary compatibility problems), and can make semi-independent decisions on when to deploy new versions of their components.
On the other hand, this freedom of decision and operation comes with additional labour: teams have to maintain/write tedious serialisation logic to convert from low level payloads (HTTP/JSON) to domain-specific data-types, in order to talk to other components of the now-distributed application. Additionally, each component-to-component interaction comes with a hard boundary that induces additional computational cost and latency. Moreover, each team being responsible for the deployment of their components induces a fair bit of complexity and cognitive overhead, as ad-hoc CI pipelines/Bash scripts and YAML configurations become necessary. Those things steal time away from where the business value is, namely domain-specific logic

It's a trade-off
Neither solution is perfect: microservices allow teams to gain in autonomy and decisions power, but create additional complexity when components need to talk to one another, and monoliths get faster/safer component interactions whilst suffering from lengthy build/deploy times and whilst preventing teams from evolving and scaling the components they own in autonomy.
The Unicorn
Reflecting on the trade-off allows us to list the properties that are interesting from both sides. What we'd like to have, ultimately, is :
- fast build/deploy times
- compile-time checks for component interactions, even across team boundaries
- ability for teams to deploy their components independently from the rest of the system
- fast component-to-component calls (as fast as function-calls)
- ability for teams to update the libraries they use without jeopardising the rest of the system
Are we stuck in this standoff ?
Alright so hopefully you've realised that this lame exposition is only there as a segue into the subject of this very post: namely the aspects of Unison that improve the status quo. In order to understand how, we have to dig a little into what Unison does differently from traditional languages. Not gonna lie: I'm finding it very hard to explain it in the sequential fashion that a blogpost required: my mind is more like a wall-of-crazy than Sherlock's mind palace. You can save yourself the pain of following my very imperfect explanation and go directly to the summary of the authors of Unison.
Anyway, here goes:
Unison's code model
Most things in the Unison language are terms. There's no arbitrary grouping construct like classes/interfaces that couples the compilation of separate terms.
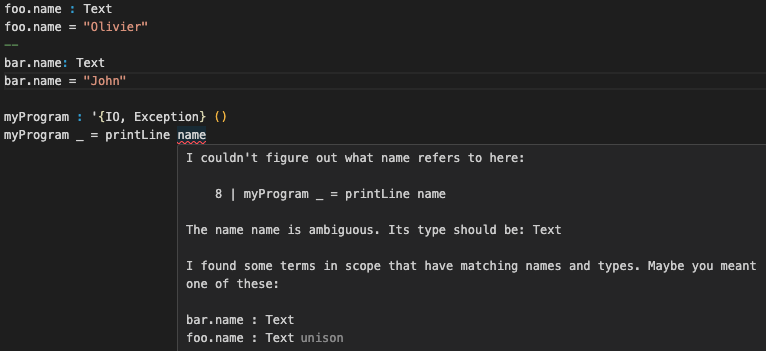
name : Text
name = "Olivier"
Every term is uniquely identified by the hash of its contents, and its name is an "alias" rather than an identifier. It also means that two functions having an identical definitions, such as in this snippet :
name : Text
name = "Olivier"
firstName: Text
firstName = "Olivier"
... are quite literally the same in Unison, meaning that it does not keep two copies in its store.
Aliases can be defined with arbitrary namespaces
foo.name: Text
foo.name = "Olivier"
bar.name: Text
bar.name = "John"
When you pull a library, all the terms it contains become re-aliased by prefixing their original aliases with the identifier of the author/provider, the name of library, and the version.
In the context of a project, you can refer to a term via partial aliases, for instance baz, or bar.baz, or foo.bar.baz, or author_lib_0_0_1.foo.bar.baz. The compiler will only force you to be more precise if the partial alias you're trying to use is ambiguous. This is quite ergonomic and convenient, as you're seldom forced to fully-qualify the functions you want to use in order to disambiguate.
A Unison codebase is not a bunch of files, but rather a granular Table[Hash, Code]. When you push code to a unison remote repository, you're sending the diff between what you have in your project, and what is already present remotely. The remote repository then re-hashes each code entry to ensure that the table is valid. This implies that no recompilation (as in parsing, type-checking) needs to occur when you pull the code from remote. The hash-verification is sufficient to ensure the code is valid and can be run.
Mahoosive benefits
The fact that Unison stores its code differently allows it to solve the status-quo problems I described earlier
It solves source/binary compatibility
- Unison allows for several versions of libraries to co-exist in the same project, exposed under different aliases, without a large impact on the ergonomics of the language. This solves source-compatibility.
- The fact that Unison uses content hashes to identify terms mean that you can never accidentally substitute one function for another by pulling another library. The full call-graph of a term is recursively hashed. If you want to update a term deep in a call-graph of your project and change its definition, the Unison tooling will help you crawl through the reverse-call-graph of your project to ensure new versions of the functions are compiled and aliases are updated, giving you opportunities to make decisions along the way. But because the code is content-addressed, it's completely immutable, which solves binary-incompatibility (which arises for mutable code references).
It solves the issue of bundling
The granularity and immutability of code means that it's not required to create bundles of code/applications. A single line changed in a will result in a minimal diff between two versions of an application. This diff will contain only things that are logically related, rather than hundreds of megabytes worth of bundles that stems from un-warranted coupling (classes/jars/docker images).

Even better: it makes every term and function fully serialisable at runtime. This allows deployment logic to be written directly in Unison, and co-located with application logic. It also means that it's possible for running nodes to send functions to each-other on the fly (as functions are terms themselves, and therefore serialisable). Virtually speaking, one could recreate a lot of features Apache Spark directly in Unison, as one of Spark's selling point is sending code across the network.
It combines benefits from both micro-services and monoliths
Because everything is serialisable, the notion of "service" basically equates to a function which may induce an I/O boundary crossing when called. This means that calling another Unison service is possible without suffering a penalty of having to manually transform high-level data into low-level HTTP/JSON, which is a time consuming and error-prone exercise.
It also means that it's possible to entrust a Cloud scheduler to dynamically reconfigure the mapping between logical components (services) to "physical" components (nodes/pods), as it is able to send code over on the fly. Such a scheduler can effectively make decisions to maximise hardware affinity between services, minimising latency in service calls by turning them into local function calls, without suffering the downsides that usually come with monolithic applications. This is called Adaptive Service Graph Compression and is likely to have tangible benefits in terms of reduced computational costs.

As an added benefits, this can greatly reduce the cognitive overhead of maintaining distributed applications, as engineers can effectively focus on the logical aspect of their software as opposed to the physical one. A car analogy would be manual gearboxes VS automatic gearboxes: driving stick is pretty cool, but it's more tiring and often less efficient than an automated gearbox.
Collateral benefits
There are a large number of other benefits, but one that's really impressive is that because everything is identified by its hash, unison-share (ie Unison's github) can store all the projects it contains in a global table. When reading code from unison-share, every single term you have access to is a clickable hyperlink and will show you to the definition and documentation (across projects/users/organisation).
Not only does it makes code extremely discoverable, but it also implies that analytics tools can be run globally across a unison-share instance, for instance to identify uses of deprecated terms. It could make tech-debt a lot easier to quantify and pay-off at the scale of the organisation.
Conclusion
There's a ton of other things about Unison that are extremely appealing, from its ability system that encapsulate interactions with the lower-level concepts in principled and safe way, to the embedded distributed storage primitives that open the door to a great many patterns that are prohibitively hard to achieve with other tech stacks.
There are still a lot of things that are missing in the Unison ecosystem, ranging from CI/CD solutions to high-level libraries to interact with other systems. But the foundations of the Unison platform I've talked about in this post are very appealing to me, so much so that if I was starting my own business that needed software running in the Cloud, I'd seriously consider Unison.